I have a bunch of BigTiff(.btf) images stored on an S3 bucket (~3TB). These images are scanned from VS160 Olympus scanner and are uncompressed. So the size of each image varies between 7GB-24GB.
I have a VM on the cloud that has 30 ocpus, 328GB RAM and 300 GB boot volume. I have configured the S3 assetstore and imported these files into a collection. When I click on the large image icon, it basically takes forever to load the image in Full resolution and if I click back, it kind of hangs. If it does load, it takes over 10-15 mins and that too not in full resolution.
I then changed Automatically use new items as large images to Automatically try to use all files as large images in the Large Image Plugin.
In this case, I can see the RAM and the disk space on the VM being eaten up until the disk space is full and I can no longer access the UI. I have to reboot. ( But I can view some of the images in Full resolution until the disk space is full).
How do the files get cached/store in the case of s3 assetstore? Does it copy all the images onto the disk? If so where exactly is it copied (in the db/assetstore location or somewhere else)?
What’s the best way to deal with this scenario? Should I add a big block volume to the VM and configure the docker-compose to store assetstore, logs and db on the block volume? We’d like these images to load rather quickly. Any advice would be much appreciated.
Tiff files have a huge number of ways that images can be stored in them. Ideally, they are stored with the image divided into tiles and into multiple resolutions, which allows efficient reading at any location. But, based on your description, my guess is that these files are stored as a single image block.
Internally, we use a number of different tile sources (libraries) to read different files. Probably the BTF files are being read via the tifffile library (but maybe the bioformats or gdal library). Whichever library is reading this is reading the whole image to return just part of it, hence the memory spike.
Maybe the btf files would read efficiently with a different tile source, in which case it would be a matter of listing that tile source as a higher priority for btf files. Or, they might be inefficient without some explicit code.
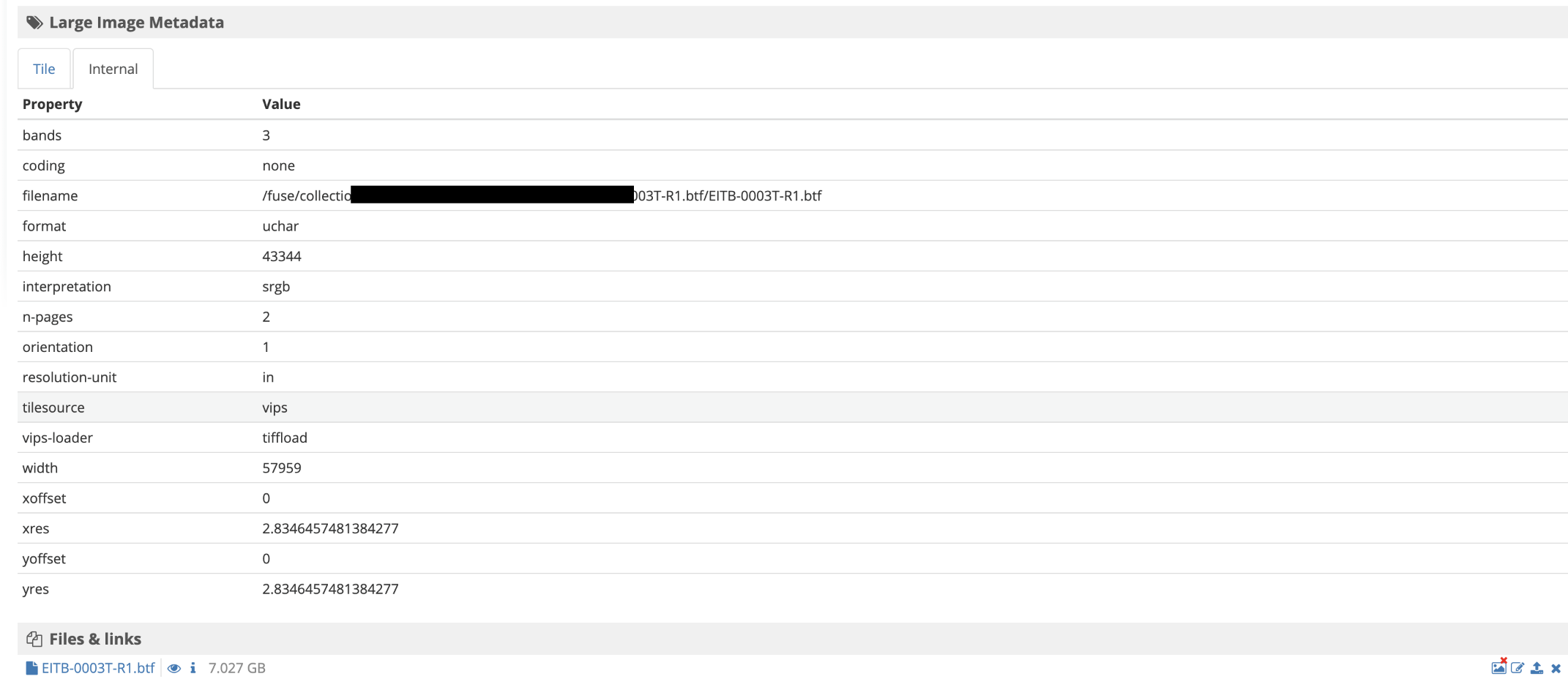
There are a couple of ways to try things out, depending on your comfort with Python or Mongo. If you have the internal metadata turned on on the item page in Girder (there is a setting in the large_image plugin settings to do this), you would see which tile source is being used.
If you can share a file (or the output of tifftools dump <path to file>), then I could state more definitively what is going on.
In looking at this, the problem is that the BTF file is untiled (stored as strips rather than tiles). All of the readers we can use (libtiff, libvips, bioformats, etc.) all read the whole file even to extract a small area.
Some readers (tifffile) are confused by the tiny secondary image.
One approach would be to convert the files from their current format to a web-optimized format (the item/{id}/tiles/convert endpoint can do this, as can the large-image-converter command line tool). This will mean having two copies of your files (the original and the web-optimized version).
The second approach would reduce memory usage but may not speed up initial viewing. This would be to modify our tiff reader (or write a different tile source) to better take advantage of the fact that the file is uncompressed. This will still be slow for the initial load, as the only way to produce low-resolution versions of the image for display is to read the whole image.
Thank you for the suggestions David. They were very helpful. I tried using the item/{id}/tiles/convert endpoint and converted it to a pyramidal tiled tiff and that seemed to greatly improve the speed at which the image loads.
The output of magick identify command on the converted image:
I’m thinking of using the large-image-converter command line tool to do the conversion, but I had a lot of trouble installing the dependencies (especially GDAL). So I tried to use the docker image with the below command.
docker pull ghcr.io/girder/large_image:latest
docker run -v /path/to/images:/opt/images ghcr.io/girder/large_image:latest large-image-converter --help
But didn’t seem to work. Is it possible to provide me with the right commands to run the docker image for large-image conversion? I can’t seem to find any documentation around the usage of docker. Thanks again.